Taking my data back from Eufy
Firstly, you might want to check out the dashboard.
I recently started a diet. One thing I decided this time around was to be heavily data driven in my weight loss, and therefore I decided to get some ‘smart’ weighing scales. I got the Eufy P1 scales which seemed to be reasonably well reviewed, and it turns out that Eufy is another name for Anker, another Chinese brand I’ve had success with in the past. I was a little irritated though when I figured out there was absolutely no way to actually get your data out of the app they provide. I wanted to get the data out of the app since the graphs that the app provides were woefully inadequate, and to me were useless. This set me on the path of building a pretty fun Goldberg-esque system to extract the data.
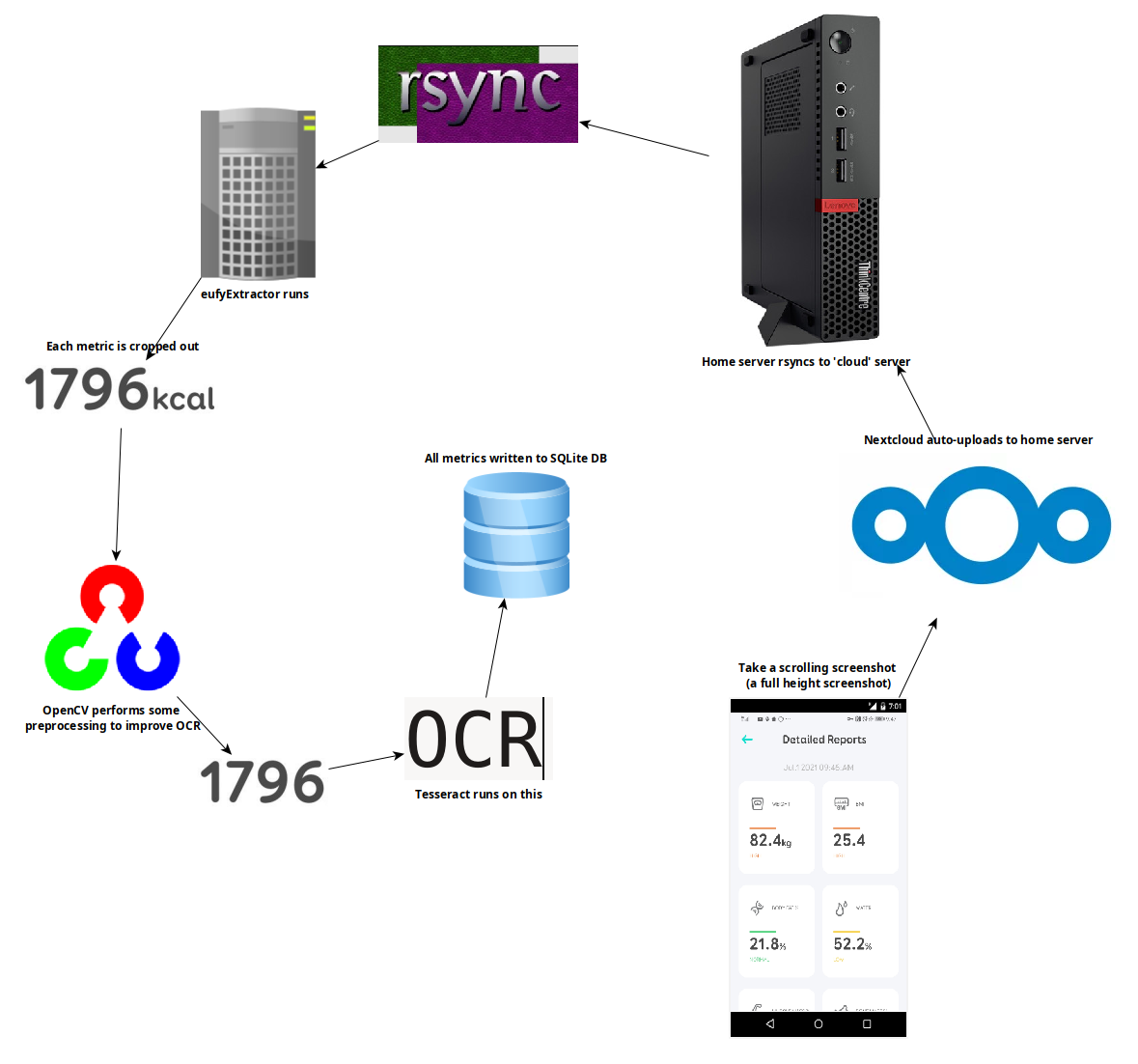
What it does
The whole process is started when I weigh myself in the morning. After I conclude weighing myself, I take a screenshot of the screen which shows my stats from that weighing session.
Next, I have Nextcloud set up locally on a home server, and my phone is configured to automatically upload all screenshots to my Nextcloud instance. My home server then will occasionally (via a cron job) upload the screenshots to my server that hosts kn100.me.
Once the screenshot has found its way to my server, a Go service I wrote notices the new file, and kicks into action. It immediately calls out to a Python script which does some pretty crazy things which I will describe in more detail later, and then returns a JSON representation of the data in the screenshot. The Go program then takes that JSON from stdout (sorry), and writes it to a Sqlite DB, and eventually the frontend will make a call out to an endpoint which returns more different JSON for the graphs to display.
What about that Python script?
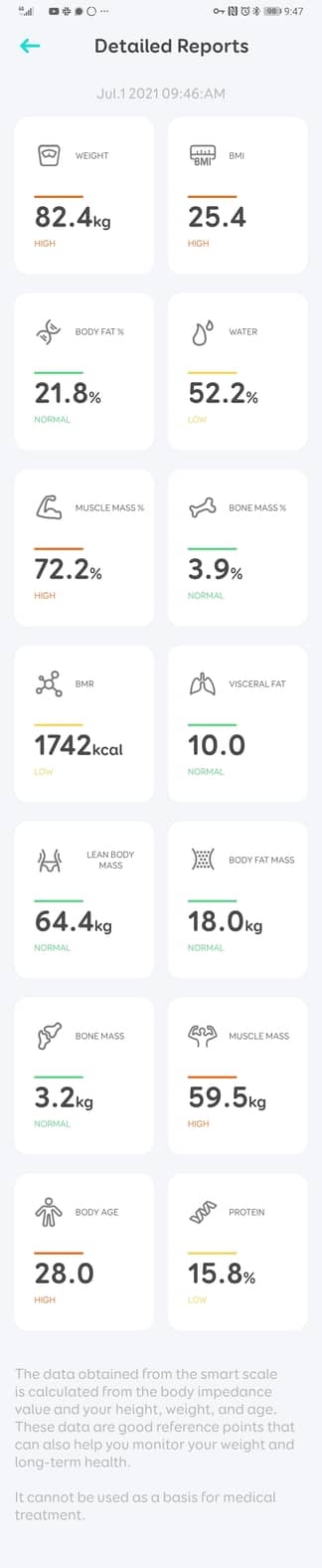
This is fun. My first attempt was completely written in Go. As you can see from the screenshot above, there are metrics spread evenly throughout the image. What I decided to do was to attempt to perform Optical Character Recognition on each metric. I found Tesseract to be a pretty good candidate for OCR, but running the entire screenshot through Tesseract was not an option, since the results of that, were…not fantastic. Tesseract seems mostly optimised for parsing blocks of text like pages from a book or receipts. Not so good for parsing freeform screenshots with text in various colours.
Instead, I firstly wrote some code that given some measurements from a screenshot, calculates where each metric is, and then crops out a square around each.
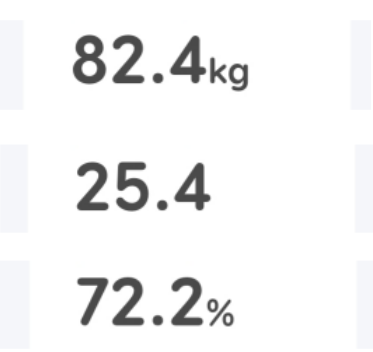
I then ran these through Tesseract, and got merely OK results. It seemed that Tesseract wasn’t getting on with the fact the unit text was smaller than the metric itself, and was occasionally confusing the last digit and the first part of the unit text to be part of the same character.
I thought about it for a while, and decided I needed some way of trimming off that unit from the end. All I cared about were the numbers, given I knew what each number at each position meant. I firstly tried a Tesseract whitelist, which would tell Tesseract only to look for certain characters. I set the whitelist to only allow digits and periods. This helped a bit, but occasionally the unit text would then be picked up as numbers, messing everything up. I really didn’t want to get into writing my own bounding box logic however, so I thought about cheap hacks to get rid of the smaller text to the right.
What I was doing in the beginning was silly. What I’d do is enormously gaussian blur the image, increase the contrast, and then sharpen it. Because the smaller details in the image (the unit text) would be less dark on the blurred image, when I re-sharpened it, those details would mostly be gone. By fine tuning how much I blurred the image along with how much brighter I made it, I was able to achieve surprisingly acceptable results. This improved OCR accuracy significantly. This approach had its own problems though, and would either remove the periods, or the remnants of what was left of the unit text would be interpreted as characters. I did try fudging it by attempting to parse the output to add in the dot where it would likely be, and to trim trailing dots, but still the accuracy wasn’t up to the standard I expected. Below is a visualisation of the blur, increase contrast, sharpen approach I was taking

For illustrative purposes I tried to reproduce the effect in Gimp, but wasn’t as successful as I was in code. The above above was as good as I got. You can see all four stages of the process here though. Firstly we blur the crap out of the metric. Then, we jack the contrast way up, and then we sharpen. I was actually able to get much better results programatically by fine tuning the numbers. The results I got from the blur, increase contrast, and sharpen approach were far better than the above visualisation lets on.

I was at my wits end at this point, and in my frustration joined #tesseract on
Libera, an IRC network. I immediately asked my question, and had an absolutely
hilarious conversation with a very kind soul there about my problem. Why
hilarious you ask? Because #tesseract has absolutely nothing to do with the
OCR software, and instead is a community around an open source FPS game.
Amusingly, one of the members there still provided me with an absolutely genius
solution which almost completely solved my problem.
kn100: I’ve got images which look like this https://nextcloud.kn100.me/s/8enRb4d9KQ2z2oE and all I want to do is detect the numbers, not the ‘kcal’ portion. With a whitelist set to just numbers, it occasionally detects the ‘kcal’ portion as numbers - I’m guessing Tesseract is choking on the fact there is a size difference in the font. Any suggestions on how I can configure Tesseract to better handle this? It’s not really an option to crop off the kcal before feeding it to tesseract - without something smart since it is unknown where exactly the numbers and the text appear in the image
@graphitemaster: has changed the topic to: Tesseract | http://tesseract.gg | Open-Source FPS Game | First Edition (May 11, 2014) released! | not tesseract-ocr | Calinou: we do OCR using pulse rifles here
@graphitemaster: kn100, Afraid you got the wrong channel. The topic wasn’t up to date since the channel moved from Freenode to Liberachat. This is a video game, not the OCR software. Though to answer your question, you could preprocess the input with opencv in Python first to remove the kcal before passing to Tesseract.
@graphitemaster: I’ve done some OCR stuff before to scrape codes from still frames and had similar problems. I found it was easier to just preprocess the input first with some CV to normalize and make Tesseract’s job easier. Something like that, if you use cv2, transform to greyscale, then use cv2.findContours, you’ll get actual bounding boxes around each character, you can very quickly tell that some of the characters will have a smaller area (maybe height is a better criteron) and you can just throw them out.
kn100: graphitemaster colour me surprised that I got help from you at all then :D Thank you so much, and sorry for misunderstanding :P
@graphitemaster: Stick around, might be some code in a minute XD
kn100: that is rather hilarious though. I might have to give Tesseract a go!
@graphitemaster: kn100, https://pastebin.com/raw/i6Zj9ebZ - t.jpg is your input
Their suggested approach was to use OpenCV. With OpenCV, I could do something a little more clever than just blurring and resharpening the image. Instead, I could use OpenCV to to find contours in the image (the edges of areas of high contrast), and measure the area of the bounding box around each contour. If a given contours bounding box wasn’t more than half of the area of the largest we’ve seen, we can throw away the pixels at that location. What was left were just the characters of the metric, which could then be stitched together again. This left me with just the numbers.
This was absolutely wonderful, and I immediately tried to port this approach to Go. Problem is, (and I mean no disrespect to the OpenCV devs!), OpenCV is a large beast. The lib that interfaces with it for Go was one called GoCV, and I just couldn’t get it to work. It was definitely something I was doing wrong but I was more interested in solving the problem at hand, so I quickly decided to do all the data processing in a Python script, which I would call out to from Go. It was a little messy, but whatever, it would work!
Onto Python, it worked great! There’s a package called opencv-python which
brings along some precompiled binaries, which worked for my use case. Upon
testing the approach that was kindly suggested to me in #tesseract, I realised
it only partially solved my problem, as it omitted periods in metrics. This was
easily rectifiable however, by adding a lower bound to the area of characters
that get thrown away. Again, by fine tuning, I was able to reliably extract just
the number portion of the screenshot.
Next up was the date parsing. This would be straight forward, but the EufyLife app has a fairly insane date format that seems to arbitrarily change. Sometimes days would have one digit, sometimes they’d have two. Sometimes hours would have one digit, sometimes they’d have two. This led to me writing some fairly horrific date parsing logic that I’m not proud of to get the date into a regular format to be parsed.
Past this point, the OCR results were almost perfect, but still not 100%. Often, the OCR would confuse the digit ‘5’ for ‘9’. What seemed to help a lot here was ’eroding’ the text to reduce how ‘bold’ it was, as well as introducing more space between each character. After this, the output from Tesseract has been entirely accurate for every metric I’ve checked.
Deploying it somewhere
One thing I was not prepared for is what a pain in the proverbials deploying Python code is. I’ve gotten so used to compiling a Go binary and having it just work, that I wasn’t prepared for deploying Python. Suffice to say, I ended up containerising it, but for reasons I am currently not completely aware of, the Docker container has to have a bunch of X11 related dependencies installed for OpenCV to work. I know that I’ve got some learning to do here. Python is not a language I’ve ever really used before, but writing Python was fairly enjoyable. I can see why Data people seem to really like it. I might end up rewriting the entire lot in Python, or I might end up trying harder to get OpenCV to work in Go, but for now this solution means I can weigh myself in the morning, take a screenshot, and about 20 seconds later it’s in a dashboard with graphs that aren’t entirely useless. Result!
A message to Eufy
Please, please provide some easy way to access this data. I don’t care if it gets exported as a CSV or if I have to query some API, just please give your users their data on request. Your in app graphs are absolutely useless, and even if they weren’t, why not just give this data up? For people like me who are a bit insane, we like data. we collect stupid amounts about ourselves. Your product becomes infinitely more valuable when you allow the user to extend it as they see fit. I know you’ve got the data, you’re logging it to some form of API somewhere, and even exporting it to Google Fit/Fitbit/Apple Health. Why not just allow me to query that API? The data is mine, give it to me!
Let me know what you thought! Hit me up on Mastodon at @kn100@fosstodon.org.